思维框架
对共识的理解
傻逼的共识也是共识:傻逼多、有共识、也会产生价值。
引用自:李笑来
algorithms
Binary Search
Template
#![allow(unused)] fn main() { fn check(mid: i32) -> bool { todo!() } fn binary_search() -> i32 { let mut left = 0; let mut right = i32::MAX; while left < right { let mid = left + (right - left) / 2; if check(mid) { left = mid; } else { right = mid - 1; } } left } }
Key Approaches
Credit to @Lee215
-
use
left < rightorleft <= rightto make the binary search process easier, we do not handle the
left == rightcase in the loop. Instead, we will try to make the leastleftindex to point to the correct answer that we are looking for. -
use
mid = left + (right - left) / 2ormid = left + (right - left + 1) / 2- use
mid = left + (right - left) / 2to find the index of the first valid element - use
mid = left + (right - left + 1) / 2to find the index of the last valid element
- use
Search for the first index of the valid value
0 1 2 3 4 5 6 7 8 9
--- --- --- --- --- --- --- --- --- ---
| 0 | 0 | 1 | 1 | 2 | 2 | 2 | 3 | 3 | 3 |
--- --- --- --- --- --- --- --- --- ---
^
|
target
^ ^ ^ ^ ^ ^
| | | | | |
valid
fn main() { let list = vec![0, 0, 1, 1, 2, 2, 2, 3, 3, 3]; let k = 2; let res = binary_search_first_valid(list, k); println!("Result: {:?}", res); } fn binary_search_first_valid(list: Vec<i32>, target: i32) -> usize { fn check(list: &Vec<i32>, mid: usize, target: i32) -> bool { list[mid] >= target } let mut left = 0; let mut right = list.len(); while left < right { let mid = left + (right - left) / 2; if check(&list, mid, target) { right = mid; } else { left = mid + 1; } } left }
Search for the last index of the valid value
0 1 2 3 4 5 6 7 8 9
--- --- --- --- --- --- --- --- --- ---
| 0 | 0 | 1 | 1 | 2 | 2 | 2 | 3 | 3 | 3 |
--- --- --- --- --- --- --- --- --- ---
^
|
target
^ ^ ^ ^ ^ ^ ^
| | | | | | |
valid
fn main() { let list = vec![0, 0, 1, 1, 2, 2, 2, 3, 3 ,3]; let k = 2; let res = binary_search_last_valid(list, k); println!("Result: {:?}", res); } fn binary_search_last_valid(list: Vec<i32>, target: i32) -> usize { fn check(list: &Vec<i32>, mid: usize, target: i32) -> bool { list[mid] <= target } let mut left = 0; let mut right = list.len(); while left < right { let mid = left + (right - left + 1) / 2; if check(&list, mid, target) { left = mid; } else { right = mid - 1; } } left }
Search for the exact index of a valid element
0 1 2 3 4 5 6 7 8 9
--- --- --- --- --- --- --- --- --- ---
| 0 | 0 | 1 | 1 | 1 | 1 | 2 | 3 | 3 | 3 |
--- --- --- --- --- --- --- --- --- ---
^
|
target
The first approach is to use the rust built-in binary search method of a Vec
#![allow(unused)] fn main() { let list = vec![0, 0, 1, 1, 1, 1, 2, 3, 3 ,3]; let target = 2; let res = list.binary_search(&target); println!("Result: {:?}", res); // Ok(6) }
Another benefit is the built in binary search method will also yield the location where the given value should be inserted to keep the Vec in the sorted order.
#![allow(unused)] fn main() { let list = vec![0, 0, 1, 1, 1, 1, 3, 3, 3 ,3]; let target = 2; let res = list.binary_search(&target); println!("Result: {:?}", res); // Err(6) }
Let's see how can we adapt the "Search for the first index of the valid value" to do the same as the above built-in binary search function.
fn main() { let list = vec![0, 0, 1, 1, 2, 3, 3, 3, 3, 3]; let k = 2; let res = binary_search(list, k); println!("Search for 2 in the list [0, 0, 1, 1, 2, 3, 3, 3, 3, 3]"); println!("Result: {:?}", res); let list = vec![0, 0, 1, 1, 2, 3, 3, 3, 3, 3]; let k = 4; let res = binary_search(list, k); println!("Search for 4 in the list [0, 0, 1, 1, 2, 3, 3, 3, 3, 3]"); println!("Result: {:?}", res); } fn binary_search(list: Vec<i32>, target: i32) -> Result<usize, usize> { fn check(list: &Vec<i32>, mid: usize, target: i32) -> bool { list[mid] >= target } let mut left = 0; let mut right = list.len(); while left < right { let mid = left + (right - left) / 2; if check(&list, mid, target) { right = mid; } else { left = mid + 1; } } if left < list.len() { Ok(left) } else { Err(left) } }
Delta / Difference Array
The idea of prefix sum is to construct an array that record the changes happened at each index. This is often useful when deal with scheduling issue and when working with a time series of events
Schedule - bookings
|-----------------------| [0, 6]
|-----------| [2, 5]
|-------| [1, 3]
|-------------------| [2, 7]
+---+---+---+---+---+---+---+---+
0 1 2 3 4 5 6 7 8
Delta / Diff Array
1 1 2 0 -1 0 -1 -1 -1
+---+---+---+---+---+---+---+---+
0 1 2 3 4 5 6 7 8
Number of booking at each timestamp
1 2 4 4 3 3 2 1 0
+---+---+---+---+---+---+---+---+
0 1 2 3 4 5 6 7 8
Example
In the graph above we have the following 4 time slot [0, 6], [2, 5], [1, 3], [4, 7], let's say that we want to find out at each timestamp how many booking are there on the schedule. How can we figure it out?
Using a BTreeMap
#![allow(unused)] fn main() { use std::collections::BTreeMap; let schedule = vec![(0, 6), (2, 5), (1, 3), (4, 7)]; let mut delta: BTreeMap<usize, i32> = BTreeMap::new(); for (start, end) in schedule { *delta.entry(start).or_insert(0) += 1; *delta.entry(end + 1).or_insert(0) -= 1; } println!("delta - diff array: {:?}", delta); }
Using a Vec
#![allow(unused)] fn main() { use std::collections::BTreeMap; let schedule = vec![(0, 6), (2, 5), (1, 3), (4, 7)]; let mut delta = vec![0; 9]; for (start, end) in schedule { delta[start] += 1; delta[end + 1] -= 1; } let mut num_of_booking = vec![0; 9]; let mut curr_number_of_booking = 0; for i in 0..9 { curr_number_of_booking += delta[i]; num_of_booking[i] = curr_number_of_booking; } println!("delta - diff array: {:?}", delta); println!("number of booking: {:?}", num_of_booking); }
Dijkstra f64
use std::cmp::Ordering; use std::collections::BinaryHeap; #[derive(PartialEq, PartialOrd)] struct Node { node: usize, prob: f64, } impl Eq for Node {} impl Ord for Node { fn cmp(&self, other: &Self) -> Ordering { // Max-heap self.prob .partial_cmp(&other.prob) .unwrap() .then_with(|| self.node.cmp(&other.node)) } } struct Solution {} impl Solution { pub fn max_probability( n: i32, edges: Vec<Vec<i32>>, succ_prob: Vec<f64>, start: i32, end: i32, ) -> f64 { let n = n as usize; let start = start as usize; let end = end as usize; let graph = Self::convert_edge_list_to_adjacency_list(edges, succ_prob, n); // Dijkstra // Edges: E // Nodes/Vertices: V // // Time Complexity: O(E + V log V ) // Space Complexity: O(V) let mut cost = vec![0.0; n]; cost[start] = 1.0; let mut pq: BinaryHeap<Node> = BinaryHeap::new(); pq.push(Node { node: start, prob: 1.0, }); while let Some(node) = pq.pop() { for (next, edge_prob) in &graph[node.node] { let prob = *edge_prob * node.prob; if prob > cost[*next] { cost[*next] = prob; pq.push(Node { node: *next, prob }) } } } cost[end] } /// Edges: E /// Nodes/Vertices: V /// /// Time Complexity: O(E) /// Space Complexity: O(V + E) fn convert_edge_list_to_adjacency_list( edges: Vec<Vec<i32>>, succ_prob: Vec<f64>, n: usize, ) -> Vec<Vec<(usize, f64)>> { let mut graph: Vec<Vec<(usize, f64)>> = vec![vec![]; n]; for i in 0..edges.len() { let u = edges[i][0] as usize; let v = edges[i][1] as usize; let prob = succ_prob[i]; graph[u].push((v, prob)); graph[v].push((u, prob)); } graph } } fn main() { let n = 3; let edges = [[0, 1], [1, 2], [0, 2]]; let edges: Vec<Vec<i32>> = edges.into_iter().map(|e| e.to_vec()).collect(); let succ_prob = [0.5, 0.5, 0.2]; let succ_prob: Vec<f64> = succ_prob.into_iter().collect(); let start = 0; let end = 2; let res = Solution::max_probability(n, edges, succ_prob, start, end); println!("{:?}", res); }
Dijkstra i64
use std::{cmp::Ordering, collections::BinaryHeap}; #[derive(Eq, PartialEq)] struct Node { index: usize, cost: i64, } impl Ord for Node { fn cmp(&self, other: &Self) -> Ordering { // min-heap other .cost .cmp(&self.cost) .then_with(|| self.index.cmp(&other.index)) } } impl PartialOrd for Node { fn partial_cmp(&self, other: &Self) -> Option<Ordering> { Some(self.cmp(other)) } } struct Solution {} impl Solution { const MODULO: i64 = 10_0000_0007; /// Edges: E /// Nodes/Vertices: V /// /// Time Complexity: O(E) /// Space Complexity: O(V + E) fn convert_edge_list_to_adjacency_list( edges: Vec<Vec<i32>>, n: usize, ) -> Vec<Vec<(usize, i64)>> { let mut graph: Vec<Vec<(usize, i64)>> = vec![vec![]; n]; for edge in edges { let src = edge[0] as usize; let dst = edge[1] as usize; let cost = edge[2] as i64; graph[src].push((dst, cost)); graph[dst].push((src, cost)); } graph } pub fn count_paths(n: i32, roads: Vec<Vec<i32>>) -> i32 { let n = n as usize; let graph: Vec<Vec<(usize, i64)>> = Self::convert_edge_list_to_adjacency_list(roads, n); let mut cost: Vec<i64> = vec![i64::MAX; n]; let mut path_count: Vec<i64> = vec![0; n]; // Dijkstra // Edges: E // Nodes/Vertices: V // // Time Complexity: O(E + V log V ) // Space Complexity: O(V) let mut pq: BinaryHeap<Node> = BinaryHeap::new(); path_count[0] = 1; cost[0] = 0; pq.push(Node { index: 0, cost: 0 }); while let Some(node) = pq.pop() { for (next_index, next_cost) in &graph[node.index] { if node.cost + *next_cost > cost[*next_index] { continue; } else if cost[*next_index] == node.cost + *next_cost { path_count[*next_index] = (path_count[*next_index] + path_count[node.index]) % Self::MODULO; } else { cost[*next_index] = node.cost + *next_cost; path_count[*next_index] = path_count[node.index]; pq.push(Node { index: *next_index, cost: node.cost + *next_cost, }); } } // println!("{:?} {:?} {:?}", node.index, node.cost, node.path); // println!("{:?}", cost); // println!("{:?}", path_count); } path_count[n - 1] as i32 } } fn main() { let n = 7; let roads = [ [0, 6, 7], [0, 1, 2], [1, 2, 3], [1, 3, 3], [6, 3, 3], [3, 5, 1], [6, 5, 1], [2, 5, 1], [0, 4, 5], [4, 6, 2], ]; let roads = roads.into_iter().map(|r| r.to_vec()).collect(); let res = Solution::count_paths(n, roads); println!("{:?}", res); }
Math
Greatest Common Divisor
fn main() { println!("gcd of 10 and 5 is {}", gcd(10, 5)); println!("gcd of 11 and 22 is {}", gcd(11, 22)); println!("gcd of 44 and 63 is {}", gcd(44, 63)); println!("gcd of 44 and 64 is {}", gcd(44, 64)); } fn gcd(a: i32, b: i32) -> i32 { if b != 0 { gcd(b, a % b) } else { a } }
Least Common Multiple
fn main() { println!("lcm of 10 and 5 is {}", lcm(10, 5)); println!("lcm of 11 and 22 is {}", lcm(11, 22)); println!("lcm of 44 and 63 is {}", lcm(44, 63)); println!("lcm of 44 and 64 is {}", lcm(44, 64)); } fn gcd(a: i32, b: i32) -> i32 { if b != 0 { gcd(b, a % b) } else { a } } fn lcm(a: i32, b: i32) -> i32 { a * b / gcd(a, b) }
Fraction Comparison / Slope Comparison
When comparing a/b and x/y in computer science, we can use a floating point (f64 in rust or double in java). Nevertheless, due to the limited precision of IEEE 754-1985 / IEEE 754-2008 floating point standard, directly checking a / b == x / y might not yield the correct result. Hence, we have two alternative approaches:
-
Cross Product
Instead of checking
a / b == x / y, we can checka * y == x * b. -
GDC Slope
If
a / bandx / yrepresent the same slope, thena / gcd(a, b) == x / gcd(x, y)andb / gcd(a, b) == y / gcd(x, y)must be true.
#![allow(unused)] fn main() { fn gcd(a: i128, b: i128) -> i128 { if b != 0 { gcd(b, a % b) } else { a } } let (a, b) = (1, 1); let (x, y) = (999999999999999999, 1000000000000000000); println!("a: {}", a); println!("b: {}", b); println!("x: {}", x); println!("y: {}", y); let equal = a as f64 / b as f64 == x as f64 / y as f64; let equal_cross_product = a * y == x * b; let equal_gdc = a / gcd(a, b) == x / gcd(x, y) && b / gcd(a, b) == y / gcd(x, y); println!("Standard approach: {}", equal); println!("Cross product approach: {}", equal_cross_product); println!("GDC approach: {}", equal_gdc); }
Prime List - A list of all prime numbers
#![allow(unused)] fn main() { fn prime_list(max_value: usize) -> Vec<usize> { let mut is_prime = vec![true; max_value + 1]; is_prime[0] = false; is_prime[1] = false; for i in 2..=max_value { if is_prime[i] { let mut factor = 2; while factor * i <= max_value { is_prime[factor * i] = false; factor += 1; } } } (0..=max_value).filter(|i| is_prime[*i]).collect() } }
Prime Set - Unique prime divisors of number n
#![allow(unused)] fn main() { fn prime_set(n: usize) -> HashSet<usize> { for i in 2..((n as f64).sqrt() as usize + 1) { if n % i == 0 { let mut set = prime_set(n / i); set.insert(i); return set; } } HashSet::from([n]) } }
Prefix Sum
The idea of prefix sum is to construct an array that for each index prefix_sum[index] represent the total cumulative sum of all element between the first element to the element for the given index. This is an useful tool when there are a lot of operation of getting the sum of a sub-array of the inputting array.
numbers
----- ----- ----- ----- ----- ----- -----
| 4 | 6 | 10 | 40 | 5 | 8 | 30 |
----- ----- ----- ----- ----- ----- -----
0 1 2 3 4 5 6
prefix-sum (inclusive)
----- ----- ----- ----- ----- ----- -----
| 4 | 10 | 20 | 60 | 65 | 73 | 103 |
----- ----- ----- ----- ----- ----- -----
0 1 2 3 4 5 6
prefix-sum (exclusive)
----- ----- ----- ----- ----- ----- ----- -----
| 0 | 4 | 10 | 20 | 60 | 65 | 73 | 103 |
----- ----- ----- ----- ----- ----- ----- -----
0 1 2 3 4 5 6 7
Variables
numbersthe input arrays that contains numbers with length ofnprefix_sumthe prefix sum array
Two types of prefix sum
-
inclusive prefix sum
prefix_sum[i] = prefix_sum[i - 1] + number[i]- The value
prefix_sum[i]includesnumber[i]and all numbers comes beforenumber[i]
-
exclusive prefix sum
prefix_sum[i] = prefix_sum[i - 1] + number[i - 1]- The value
prefix_sum[i]does notnumber[i]but includes all numbers comes beforenumber[i]
For the sake of simplicity and to avoid accessing numbers with native index, I always use the exclusive prefix sum
How to build the prefix sum array:
#![allow(unused)] fn main() { let numbers = vec![4, 6, 10, 40, 5, 8, 30]; let mut prefix_sum = vec![0; numbers.len() + 1]; for i in 0..numbers.len() { prefix_sum[i + 1] = prefix_sum[i] + numbers[i]; } println!{"numbers: {:?}", numbers}; println!{"prefix_sum: {:?}", prefix_sum}; }
How to access the sum of all element with index [i, j):
#![allow(unused)] fn main() { let prefix_sum = vec![0, 4, 10, 20, 60, 65, 73, 103]; let (i, j) = (2, 5); let sum = prefix_sum[j] - prefix_sum[i]; println!("sum of sub array [10, 40, 5]: {:?}", sum); }
Union Find
#![allow(unused)] fn main() { struct UnionFind { parents: Vec<usize>, } impl UnionFind { fn new(len: usize) -> Self { UnionFind { parents: (0..len).collect(), } } fn find(&mut self, node: usize) -> usize { if self.parents[node] == node { node } else { self.parents[node] = self.find(self.parents[node]); self.parents[node] } } fn union(&mut self, a: usize, b: usize) { let a = self.find(a); let b = self.find(b); self.parents[a] = b; } } }
Data Structure
Segment Tree Range Sum
use std::{ cmp::Ordering, collections::{BinaryHeap, HashMap, HashSet}, fmt::{Binary, Debug}, }; fn main() { let vec = vec![1, 3, 5]; let mut num_array = NumArray::new(vec); println!("{:?}", num_array.sum_range(0, 2)); println!("{:?}", num_array.update(1, 2)); println!("{:?}", num_array.sum_range(0, 2)) } struct SegmentTreeNode<'a, T> { left_node: Option<Box<SegmentTreeNode<'a, T>>>, right_node: Option<Box<SegmentTreeNode<'a, T>>>, left_index: usize, right_index: usize, info: T, operation: &'a dyn Fn(&T, &T) -> T, } impl<'a, T> Debug for SegmentTreeNode<'a, T> where T: Debug, { fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result { f.debug_struct("SegmentTreeNode") .field("left_node", &self.left_node) .field("right_node", &self.right_node) .field("left_index", &self.left_index) .field("right_index", &self.right_index) .field("info", &self.info) .finish() } } impl<'a, T> SegmentTreeNode<'a, T> where T: Copy + Debug, { fn new_from_vec(vec: Vec<T>, operation: &'a dyn Fn(&T, &T) -> T) -> Self { let left_index = 0; let right_index = vec.len() - 1; Self::new_from_slice(&vec, left_index, right_index, operation) } fn new_from_slice( slice: &[T], left_index: usize, right_index: usize, operation: &'a dyn Fn(&T, &T) -> T, ) -> Self { if left_index == right_index { SegmentTreeNode { left_node: None, right_node: None, left_index, right_index, info: slice[0], operation, } } else { let mid_index = (left_index + right_index) / 2; let left_node = Self::new_from_slice( &slice[0..=(mid_index - left_index)], left_index, mid_index, operation, ); let right_node = Self::new_from_slice( &slice[(mid_index - left_index + 1)..=(right_index - left_index)], mid_index + 1, right_index, operation, ); let info = operation(&left_node.info, &right_node.info); SegmentTreeNode { left_node: Some(Box::new(left_node)), right_node: Some(Box::new(right_node)), left_index, right_index, info, operation, } } } fn update_index(&mut self, index: usize, info: T) { if self.left_index == index && self.right_index == index { self.info = info; } match (&mut self.left_node, &mut self.right_node) { (Some(left_node), Some(right_node)) => { if left_node.right_index >= index { left_node.update_index(index, info); } else { right_node.update_index(index, info); } self.info = (self.operation)(&left_node.info, &right_node.info); } _ => (), } } fn range_operation(&self, left_index: usize, right_index: usize) -> T { if left_index < self.left_index || right_index > self.right_index { panic!("indexes out of range") } if left_index == self.left_index && right_index == self.right_index { return self.info; } match (&self.left_node, &self.right_node) { (Some(left_node), Some(right_node)) => { if right_index <= left_node.right_index { left_node.range_operation(left_index, right_index) } else if left_index >= right_node.left_index { right_node.range_operation(left_index, right_index) } else { (self.operation)( &left_node.range_operation(left_index, left_node.right_index), &right_node.range_operation(right_node.left_index, right_index), ) } } (Some(left_node), None) => left_node.range_operation(left_index, right_index), (None, Some(right_node)) => right_node.range_operation(left_index, right_index), (None, None) => unreachable!(), } } } struct NumArray<'a> { node: SegmentTreeNode<'a, i32>, } impl NumArray<'_> { fn new(nums: Vec<i32>) -> Self { NumArray { node: SegmentTreeNode::new_from_vec(nums, &|a: &i32, b: &i32| a + b), } } fn update(&mut self, index: i32, val: i32) { self.node.update_index(index as usize, val) } fn sum_range(&self, left: i32, right: i32) -> i32 { self.node.range_operation(left as usize, right as usize) } }
Segment Tree Min Index
use std::{ fmt::Debug, cmp::{Ordering, Reverse}, collections::{BinaryHeap, HashMap, HashSet}, fmt::Binary, hash::Hash, }; fn main() { let target = vec![1,2,3,2,1]; let res = Solution::min_number_operations(target); println!("{:?}", res); } struct Solution; impl Solution { pub fn min_number_operations(target: Vec<i32>) -> i32 { let root = SegmentTreeNode::new_from_vec(&target); Self::dfs(0, target.len() - 1, 0, &root, &target) } fn dfs(left_idx: usize, right_idx:usize, base: i32, root: &SegmentTreeNode, target: &Vec<i32>) -> i32 { if right_idx < left_idx { return 0; } if left_idx == right_idx { return target[left_idx] - base; } let (min_idx, min_val) = root.query_range_min(left_idx, right_idx); let mut res = min_val - base; if min_idx > 0 { res += Self::dfs(left_idx, min_idx - 1, min_val, root, target); } res += Self::dfs(min_idx + 1, right_idx, min_val, root, target); res } } #[derive(Debug)] struct SegmentTreeNode { left_node: Option<Box<SegmentTreeNode>>, right_node: Option<Box<SegmentTreeNode>>, left_index: usize, right_index: usize, min_idx: usize, min_val: i32, } impl SegmentTreeNode{ fn new_from_vec(vec: &Vec<i32>) -> Self { let left_index = 0; let right_index = vec.len() - 1; Self::new_from_slice(&vec, left_index, right_index) } fn new_from_slice( slice: &[i32], left_index: usize, right_index: usize, ) -> Self { if left_index == right_index { SegmentTreeNode { left_node: None, right_node: None, left_index, right_index, min_idx: left_index, min_val: slice[0], } } else { let mid_index = (left_index + right_index) / 2; let left_node = Self::new_from_slice( &slice[0..=(mid_index - left_index)], left_index, mid_index, ); let right_node = Self::new_from_slice( &slice[(mid_index - left_index + 1)..=(right_index - left_index)], mid_index + 1, right_index, ); let (min_idx, min_val) = if left_node.min_val < right_node.min_val { (left_node.min_idx, left_node.min_val) } else { (right_node.min_idx, right_node.min_val) }; SegmentTreeNode { left_node: Some(Box::new(left_node)), right_node: Some(Box::new(right_node)), left_index, right_index, min_idx, min_val, } } } fn query_range_min(&self, left_index: usize, right_index: usize) -> (usize, i32) { if right_index < self.left_index || left_index > self.right_index { (usize::MAX, i32::MAX) } else if left_index <= self.left_index && right_index >= self.right_index { (self.min_idx, self.min_val) } else { let (left_min_idx, left_min_val) = self.left_node.as_ref().unwrap().query_range_min(left_index, right_index); let (right_min_idx, right_min_val) = self.right_node.as_ref().unwrap().query_range_min(left_index, right_index); if left_min_val < right_min_val { (left_min_idx, left_min_val) } else { (right_min_idx, right_min_val) } } } }
Trie
#![allow(unused)] fn main() { #[derive(Debug)] struct Trie { value: char, children: HashMap<char, Trie>, } impl Trie { fn new(value: char) -> Trie { Trie { value, children: HashMap::new(), } } fn from_vec_string(words: Vec<String>) -> Trie { let mut root = Trie::new(' '); words.into_iter().for_each(|word| root.add_string(word)); root } fn from_vec_vec_char(words: &Vec<Vec<char>>) -> Trie { let mut root = Trie::new(' '); words.iter().for_each(|word| root.add_vec_char(word)); root } fn add_string(&mut self, word: String) { let word = word.chars().collect(); self.add_vec_char(&word) } fn add_vec_char(&mut self, word: &Vec<char>) { let mut node = self; for character in word.iter() { node = node .children .entry(*character) .or_insert(Trie::new(*character)) } } } }
Rust
Rust BTreeMap and BTreeSet
In rust
- the
std::collections::BTreeMapis the implementation of a sorted map. - the
std::collections::BTreeSetis the implementation of a sorted set.
Floor and Ceil
Floor: The Entry with the Greatest Key that is Less or Equal to a Given Key
#![allow(unused)] fn main() { map.range(..=key).next_back().unwrap(); }
Ceil: The Entry with the Least key that is Greater or Equal to a Given Key
#![allow(unused)] fn main() { map.range(key..).next().unwrap(); }
First
#![allow(unused)] fn main() { let set = BTreeSet::from([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]); // unstable approach: need `#![feature(map_first_last)]` feature flag println!("{:?}", set.first()); // current approach: println!("{:?}", set.range(..).next()); }
Last
#![allow(unused)] fn main() { let set = BTreeSet::from([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]); // unstable approach: need `#![feature(map_first_last)]` feature flag println!("{:?}", set.last()); // current approach: println!("{:?}", set.range(..).next_back()); }
Remove all elements in a given range
NOTE: This might not be the most idiomatic rust approach
Instead of removing elements from the range one by one, we have to filter out of the element in the range and then re-create the tree-map.
use std::collections::BTreeMap; fn main() { let mut map: BTreeMap<usize, usize> = BTreeMap::new(); map.insert(10, 10); map.insert(20, 20); map.insert(30, 30); map.insert(40, 40); map.insert(50, 50); map = map .into_iter() .filter(|(key, _)| *key < 20 || *key >= 40) .collect(); println!("{:?}", map); }
How does it work?
#![allow(unused)] fn main() { pub fn range<T, R>(&self, range: R) -> Range<'_, K, V> }
BTreeMap has an range method that takes a range as input and will output all the entries from the map with a key that is within the given range.
use std::collections::BTreeSet; fn main() { let set = BTreeSet::from([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]); // [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] let res = set.range(..); println!("{:?}", res); // [5, 6, 7, 8, 9] let res = set.range(5..); println!("{:?}", res); // [0, 1, 2, 3, 4] let res = set.range(..5); println!("{:?}", res); // [0, 1, 2, 3, 4, 5] let res = set.range(..=5); println!("{:?}", res); // [4, 5, 6] let res = set.range(4..=6); println!("{:?}", res); }
LinkedList
Let's first take a look at how LeetCode define the LinkedList in rust
#![allow(unused)] fn main() { #[derive(PartialEq, Eq, Clone, Debug)] pub struct ListNode { pub val: i32, pub next: Option<Box<ListNode>>, } }
As LeetCode is using Box as the pointer to point to the next node. It does not allow multiple reference to the same node. Hence, to make our life easier, we would like to change the ListNode definition to:
#![allow(unused)] fn main() { #[derive(PartialEq, Eq, Clone, Debug)] pub struct MutListNode { pub val: i32, pub next: Option<Rc<RefCell<MutListNode>>>, } }
- With
Rc<T>, we allow multiple ownership to the sameMutListNode - With
RefCell<T>, we allow interior mutability for the heap allocatedMutListNode
To convert between the LeetCode official ListNode and the mutable multi-referencing MutListNode we would need the following conversion utility functions
From Option<Box<ListNode>> to Option<Rc<RefCell<MutListNode>>>
#![allow(unused)] fn main() { fn to_mut_list_node(node: Option<Box<ListNode>>) -> Option<Rc<RefCell<MutListNode>>> { match node { None => None, Some(node) => Some(Rc::new(RefCell::new(MutListNode { val: node.val, next: to_mut_list_node(node.next), }))), } } }
From Option<Rc<RefCell<MutListNode>>> to Option<Box<ListNode>>
#![allow(unused)] fn main() { fn to_list_node(node: Option<Rc<RefCell<MutListNode>>>) -> Option<Box<ListNode>> { match node { None => None, Some(node) => Some(Box::new(ListNode { val: node.borrow().val, next: to_list_node(node.borrow().next.clone()), })), } } }
Source Code
#![allow(unused)] fn main() { #[derive(PartialEq, Eq, Clone, Debug)] pub struct ListNode { pub val: i32, pub next: Option<Box<ListNode>>, } impl ListNode { #[inline] fn new(val: i32) -> Self { ListNode { next: None, val } } } #[derive(PartialEq, Eq, Clone, Debug)] pub struct MutListNode { pub val: i32, pub next: Option<Rc<RefCell<MutListNode>>>, } impl MutListNode { #[inline] fn new(val: i32) -> Self { MutListNode { next: None, val } } } fn to_mut_list_node(node: Option<Box<ListNode>>) -> Option<Rc<RefCell<MutListNode>>> { match node { None => None, Some(node) => Some(Rc::new(RefCell::new(MutListNode { val: node.val, next: to_mut_list_node(node.next), }))), } } fn to_list_node(node: Option<Rc<RefCell<MutListNode>>>) -> Option<Box<ListNode>> { match node { None => None, Some(node) => Some(Box::new(ListNode { val: node.borrow().val, next: to_list_node(node.borrow().next.clone()), })), } } fn vec_to_linked_list(vec: Vec<i32>) -> Option<Box<ListNode>> { let mut root = ListNode::new(0); let mut curr = &mut root; for n in vec { curr.next = Some(Box::new(ListNode::new(n))); curr = curr.next.as_mut().unwrap(); } root.next } fn linked_list_to_vec(node: Option<Box<ListNode>>) -> Vec<i32> { let mut vec = vec![]; let mut curr = node; while curr != None { vec.push(curr.as_ref().unwrap().val); curr = curr.unwrap().next; } vec } fn vec_to_mut_linked_list(vec: Vec<i32>) -> Option<Rc<RefCell<MutListNode>>> { let root = Rc::new(RefCell::new(MutListNode::new(0))); let mut curr = root.clone(); for n in vec { curr.borrow_mut().next = Some(Rc::new(RefCell::new(MutListNode::new(n)))); let next = curr.borrow().next.clone().unwrap(); curr = next; } let node = root.borrow().next.clone(); node } fn mut_linked_list_to_vec(node: Option<Rc<RefCell<MutListNode>>>) -> Vec<i32> { let mut res = vec![]; let mut curr = node; while let Some(curr_node) = curr { res.push(curr_node.borrow().val); curr = curr_node.borrow().next.clone(); } res } }
Two Dimensional Matrix
Valid Neighbors
#![allow(unused)] fn main() { fn get_neighbor( board: &Vec<Vec<char>>, row_idx: usize, col_idx: usize, ) -> Vec<(usize, usize)> { let mut neighbor = vec![]; let row_len = board.len(); let col_len = board[0].len(); if row_idx > 0 { neighbor.push((row_idx - 1, col_idx)); } if col_idx > 0 { neighbor.push((row_idx, col_idx - 1)); } if row_idx + 1 < row_len { neighbor.push((row_idx + 1, col_idx)); } if col_idx + 1 < col_len { neighbor.push((row_idx, col_idx + 1)); } neighbor } }
System Design
Overview
After working in the software industry for over two years, I have learned a lot about what is hiring manager and interviewer looking for when hiring a new software development engineer. Nevertheless, to become an senior/staff engineer, there is still a long way to go. Since I departed from my first job at AWS, I have been trying to learn from lectures, books, and keynote presentations regarding the knowledge and skills that I need to tackle a system design interview. Here, is where I keep all my notes. It is not a guide, it is not a book, it is not even well-organized at all. However, it is where I keep the knowledge that I have learned so far.
System Design Interview
What is a system design interview?
- simulate in-team design process
- solve an ambiguous problem
- work with teammates/co-workers
- two co-workers working together
What are the desireable traits
- ability to collaborate with teammates
- work under pressure
- work with ambiguous problem
- constructive problem solving skills
How does the interviewer evaluate the desirable traits
- work with ambiguous problem
- does the candidate asks requirement clarification?
What are the undesirable traits
- over-engineering solution
- stubbornness
- do not answer without thinking, or without understanding the question's scope, requirements, backgrounds, etc.
Does and Don'ts
Dos
- ask for clarification, do not make assumptions without verify with the interviewer
- thinking aloud - communicate
- make multiple design proposals
- design the most critical parts first
- ask for hints when stuck
Don'ts
- do not go into detailed design in the early stage
- do not thinking alone
The approach
Approaches - four stages
- Comprehend the requirement
- Propose high-level designs
- Detailed designs
- Discussions
Stage 1: Comprehend the requirement
After the interviewer asked the question, the candidate should list out the following 5 catagories of questions on the whiteboard/notepad. Then, the candidate can asks the following questions listed for each catagories. For each question asked, take notes on the information provided by the interviewer (e.g. user is an machine learning algorithm). If the information hits a design preference, please also take notes on the possible design solution (i.e. use gRPC streaming / use map-reduce).
- User/Customer: what does the customer/end-user wants?
- who is the user? and, how will the user use the product?
- how the system will be used?
- is the data going to be retrieved frequently? in real time? or by a cron job?
- what product feature is the customer looking for?
- what problem is the customer trying to solve?
- Scale: what is the scale of the system?
- to understand how would our system handle the growing number of customers?
- how many users?
- what is the avg/p100 qps?
- what is the size of the data per request?
- do we need to handler spikes in traffic? what is the difference between peak traffic and average traffic
- when does the customer need to scale 10x/100x
- Performance: what is the performance requirement of the system?
- what is expected write-to-read delay?
- can we use batch processing?
- can we use stream processing?
- do we need to use SSE/websocket for server-side push?
- what is the expected P99 latency for read queries?
- what is expected write-to-read delay?
- Cost: what is the cost limit (budget constrain) of the system?
- should the design minimized the cost of development?
- should the design minimized the cost of dev/ops (maintenance)?
- Tech Stack: understand the technology the team is using
- AWS? GCP? Azure?
- Java? Rust? Python?
- GraphQL? gRPC? REST?
Stage 2: List out the Functional/Non-Function Requirements
After comprehend the question via asking clarification questions, the candidate can start list out the function requirements and the non-functional requirements. Make sure the interviewer is on the same page with the candidate. Also, please write down the functional requirement (i.e. API design) and non-functional requirements on the white board.
-
Functional Requirements
- What does the APIs looks like? Input parameters? Output parameters?
- What are the set of the operation that the system would support?
-
Non-Functional Requirements
- Scalability
- Performance
- Availability
- Consistency
- Cost
Stage 3: Propose high-level designs
Once we have listed out all of the functional and non-functional requirements, we can start with something sample, such as a monolith with a front-end, a backend server, and a database.
- propose design for different scales
- get the interviewers involved
- make some estimation on the traffic/scale
- dive deep only if the interviewer is asking for deeper analysis
- draw some components on the whiteboard for the high-level design
- a frontend (e.g. Website/iOS/Android)
- an api gateway
- a load balancer
- a backend service (running on EC2/ECS/AppRunner/Lambda)
- a queue (if needed) (e.g. AWS SQS/Kafka/RocketMQ)
- a database (if needed) (SQL/NoSQL) (e.g. AWS DynamoDB/Mongo/MySQL)
- a data warehouse (if needed) ()
- a batch processing service (if needed) (e.g. map-reduce)
Stage 4: Detailed design
For each components listed during the previous stage, discuss with the interviewer which part we should dive deeper to propose an detailed design. If the interviewer did not provide any preference, the candidate can pick the part that the candidate has the most in-depth knowledge to discuss/design further.
- design/discuss the api schema
- REST/gRPC/GraphQL
- design/discuss the data schema
- should we store individual data or aggregate data
- pick/discuss the database paradigms
- should we use relational or key-value stores
- pick/discuss the usage of stream/batch process for the system
- should we use a queue to buffer the request?
- should we store the data somewhere and process them together latter?
- design/discuss the backend processing service
- where to run the service? EC2/ECS/AppRunner/Lambda? trade-off? development cost vs operational cost?
- how does the logic in the back end processing services looks like?
- objected oriented design
- using local cache?
- how would it update the database?
- per-request or batched
- sync or async (queue)
- user push or server pull?
- single thread or multi thread?
- internal dead-letter queue?
Stage 5: Discussions
After finish the detailed design, the candidate and the interviewer can have a discussion regarding the pro/cons of the system such as the limitation and bottlenecks. How would the DevOps looks like during operation? How would the system handle disaster recovery? It is a great opportunity to demonstrate to the interviewer the depth and width of the knowledge of the candidate.
- limitation
- bottlenecks
- disaster recovery
- dev-ops
Question to ask:
Data schema
| Individual Data | Aggregated Data | |
|---|---|---|
| Pro |
|
|
| Con |
|
|
Ask: what is the expected data day?
- Few milliseconds/seconds -> store the individual data (stream processing)
- Few minutes -> store the individual data / aggregate the data on the fly
- Few hours -> aggregate the data using an aggregation pipeline / batch jobs (map-reduce)
Data Store Types
- Answer: How to scale write?
- Answer: How to scale reads?
- Answer: How to scale both write and reads?
- Answer: How to handle network partitions and hardware faults?
- Answer: Consistency model?
- Answer: How to recover data?
- Answer: Data security?
- Answer: How to make the data schema extensible for future changes?
Event/Request Processing Backend Service
-
Answer: How to scale?
-
Answer: How to achieve high throughput?
-
Answer: How to handle instances failure?
-
Answer: How to handle database failure? Unable to connect to database?
-
Checkpoint:
- the client write the request into a queue
- the processing server pull from the queue, process it, write to database, the update the checkpoint offset
-
Partitioning:
- have several queue (use hashing to pick a queue)
OTHERS
- Blocking or Non-Blocking I/O
- Stream Service or Batch Service
- Buffering or Batching the request
- Timeouts / Retries (Thundering heard) (Exponential Back-Off / Jitter)
- Circuit Breaker
- Load Balancing: Using a Load Balancer or Service Mesh
- Service discovery (Server-Side/Client-Side)? DNS? Auto Scaling Group? Health Check? ZooKeeper?
- Sharding (For invoke / For database) (Sharding/Partition Strategy) (Hot Partition) (Consistent Hashing)
- Replications of server node (leader/leaderless)
- Data format (JSON/BSON/Thrift/ProtoBuf)
- Testing
- correctness: unit test / functional test / integration test
- performance: load test / stress test / soak test
- monitoring: canary test
- monitoring:
- logging: cloudwatch / elastic search / kibana
- metrics: cloudwatch / grafana
- alarm: cloudwatch
References
- Alex Xu - System Design Interview - An Insider's Guide
- Mikhail Smarshchok - System Design Interview - Step By Step Guile
System Design Fundamentals
Vertical/Horizontal Scaling
- Vertical Scaling
- Horizontal Scaling
Share Nothing Architecture
- Different machine on the same machine do not share physical resources (CPU, MEM, etc.)
What makes distributed computing different from local computing
- Latency: Processor speed vs network speed
- Memory Access: No pointers -> Share data via sending messages
- Partial Failures: Unavoidable on distributed system
8 Fallacies of Distributed Systems
- The network is reliable
- Latency is ZERO
- Bandwidth is infinite
- The network is secure
- Topology does not changes
- There is only one administrator
- Transport cost $0
- The network is homogeneous
The Byzantine General Problem
Latency -> How to set a
Fischer Lynch Paterson Correctness result
- Distributed consensus is impossible when at least one process might fail
To manage uncertainty we have mitigation strategies
- APPROACH 1: Limit who can write at a given time
- Leader-Follower pattern
- APPROACH 2: Make rules for how many yes in the system
- raft - consensus algorithm
Mental modal calibration
- Incident analysis - post mortem
- fresh learning
Request Validation
- Check the request is hitting an valid API
- Check the request consist all required parameters
- Check the request parameters are within the valid range
Authentication / Authorization
- Authentication: validate the identity of the user/service
- Authorization: check the user/service has the permission for the given action
TLS / SSL Termination
- Decrypting the TLS/SSL request and pass the un-encrypted request to the backend services
Request Dispatching
- Sending the request to the appropriate backend service
Request De-duplication *
Metrics Collection *
Bulkhead Pattern
Circuit Breaker Pattern
Algorithms
When dealing with system design questions such as designing a rate limiting system, a sharding system, or a global location service, candidate can use some of the following system design algorithms during the interview.
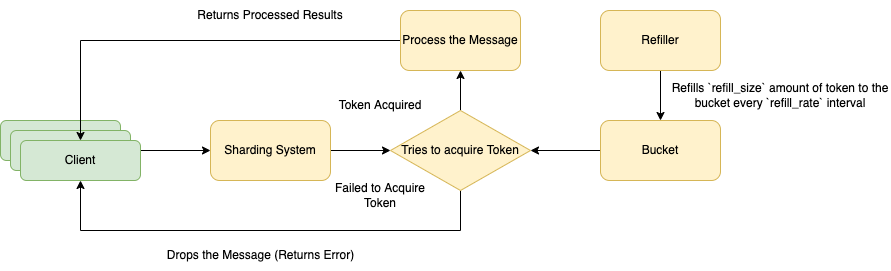
Leaky Bucket Algorithms
Use-case: Rate Limiting Systems
Process
- a client send a message to the server
- the server uses an sharding algorithms to find the corresponding bucket for the message
- the server tries to append the message to the bucket - a local message queue
- if the queue is full (i.e. has
bucket_sizemessage in the queue already), then drop the message - if the queue has space, append the message to the end of the queue
- if the queue is full (i.e. has
- the consumer will pull message from the queue with a rate of
drain_rate - the consumer process the message
Parameters
bucket_size: the maximum amount of messages can be stored in each bucketdrain_rate: the speed that the message is been consumed from the bucket

Token Bucket Algorithms
Use-case: Rate Limiting System
Process
- a client send a message to the server
- the server uses an sharding algorithms to find the corresponding bucket for the message
- the server tries to acquire a token from the bucket
- if a token is acquired, the request is processed
- if no token exist in the bucket, the request is dropped
- the bucket receive a refill of
refill_sizeamount of token each for eachrefill_rateinterval - the amount of token can be stored in the bucket is limited by the
bucket_size
Parameters
bucket_size: the maximum amount of token can be stored in each bucketrefill_size: the amount of tokenrefill_rate: the time interval between each refill
Alteration
- token per request: for each token, the system can process one message. if there are
nmessage, then it would requiresntoken from the bucket for all the message to be processed. - token per bytes: for each token, the system can process
xbyte of message. if there arenmessage each withssize, then it would requiresCEIL(x / s) * ntokens from the bucket for all message to be processed.
Consistency
Definitions
Consensus: The methods to get all of the instances/nodes in the system to agree on something.
Eventual Consistency (Convergence): All replicas in the system will eventually converge to the same value after an unspecified length of time.
Faults Tolerant: The ability of keeping the software system functioning correctly, even if some internal component is faulty.
Linearizability: The system appears as if there is only one copy of data, and all operation on the data are atomic.
Split Brain: More than one instance/node in the system believe that they are the leader in a single-leader system.
Strict Serializability / Strong One-Copy Serializability: The database/system satisfy both the serializability and linearizability requirements.
Replication Methods
- Single-Leader Replication
- Multi-Leader Replication
- Leaderless Replication
Linearizability
Requirement of Linearizability
- After one read has returned an updated value, all following read by the same client and all other clients must also returns the same updated value.
Linearizability of Replication Models
Single-leader Replication - Potentially Linearizable
Example: MongoDB with linearizable Read Concern
A single-leader replication system can become fully linearizable if the following condition are met
- All write and read are done via the leader node
- All client and knows who is the leader node.
Failover might cause the system violate the linearizability concern
- When using asynchronous replication, the lost of committed writes would cause the system to violate the linearizability and durability requirements
- When using synchronous replication, the system meet the linearizability and durability requirements, but the system will be slow.
Multi-leader Replication - Not Linearizable
Example:
Since there are multiple copy of the data handled by multiple leaders, and the replication of the data are done asynchronously, the multi-leader replication system cannot meet the linearizability requirements.
Leaderless Replication - Not Linearizable (Most of the Cases)
Example:
Consensus Algorithms - Linearizable
Example: etcd and ZooKeeper
Consensus algorithms has built-in measures to avoid/prevent split brain and stale replicas, which allows the consensus algorithms to meed the linearizability requirements.
CAP Theorem
- Characteristics
- Consistency
- All nodes on the network must return the same data
- HARD!!!!!!
- Requires: Instant and universal replication
- Eventual Consistency does not count: It's not the C in CAP
- Consistency is not a binary state, there are many degrees of consistency
- Availability
- Partition Tolerance
- Network partition occur when network connectivity between two nodes is interrupted
- Consistency
- Theorem
- NOT TRUE
- A distributed system can deliver only two of the three characteristics
- TRUE
- Partition Tolerance is required; to avoid partition tolerance, there can only be one service, which is not a distributed system
- Hence, all distributed system need to balance between consistency and availability
- NOT TRUE
Technologies
Push Notification Service Providers
For each platform (iOS, Androids, e-mails, etc), our service would need to utilized the following push notification service provider to send message to our end users.
- iOS:
- APNs - Apple Push Notification Service
- Android:
- FCM - Firebase Cloud Messaging for Android
- e-mail:
- AWS SES - Amazon Simple Email Service
- SendGrid
- MailGun
- You can always build your own email service
Four Distributed Systems Architectural Patterns - by Tim Berglund
https://www.youtube.com/watch?v=BO761Fj6HH8
| Overall Rating | Modern Three Tier | Sharded | Batch + Stream | Event Bus |
|---|---|---|---|---|
| Scalability | 4/5 | 3/5 | 5/5 | 5/5 |
| Coolness | 2/5 | 1/5 | 1/5 | 5/5 |
| Difficult | 3/5 | 4/5 | 5/5 | 4/5 |
| Flexibility | 5/5 | 3/5 | 2/5 | 5/5 |
Pattern 1 - Modern Three-Tier
----------------- ------------- ---------
|Presentation Tier|--|Business Tier|--|Data Tier|
----------------- ------------- ---------
---------- --------- -----------
| React JS |-- ELB --| Node JS |--| Cassandra |
---------- --------- -----------
- Presentation Tier - React JS
- stateless - on client
- Business Tier - Node JS
- stateless - on server
- Data Tier - Cassandra
Cassandra
- all nodes on the Cassandra cluster is the same
- assign each node a token (hash range) - for sharding
- hash the input - write/read the message from the server which contain the hash range
- write replicas to the next X nodes
strengths of the modern three tier
- reach front-end frameworks
- scalable middle tier - stateless
- infinitely scalable data tire - with cassandra
weaknesses of the modern three tier
- need to keep the middle tier stateless for scalability
Pattern - Shard
Break up the system into several shard, where each shard is a complete system
Good real-world examples:
- Slack
Stage 1
-------- ---------------------- ----------
| Client | -- | Complete Application | -- | Database |
-------- ---------------------- ----------
Stage 2
-------- -------- ---------------------- ----------
| Client | -- | | -- | Complete Application | -- | Database |
-------- | | ---------------------- ----------
-------- | | ---------------------- ----------
| Client | -- | Router | -- | Complete Application | -- | Database |
-------- | | ---------------------- ----------
-------- | | ---------------------- ----------
| Client | -- | | -- | Complete Application | -- | Database |
-------- -------- ---------------------- ----------
strengths of shard
- client isolation is easy (data and deployment)
- known, simple technologies
weaknesses of shard
- complexity: monitoring, routing
- no comprehensive view of data (need to merge all data)
- oversized shards -> a shard become a distributed system on itself
- difficult to re-shard; need to design the sharding schema upfront
Pattern 3 - Batch + Stream
Streaming vs Batch ?
- streaming - data is coming in in real time
- batch - data that is store somewhere
Batch + Stream - assumes unbounded, immutable data
-------- ---------------------- ----------
| Source | -- | batch processing | -- | Scalable |
| of | ---------------------- | Database |
| Event | ---------------------- | |
| | -- | streaming processing | -- | |
-------- ---------------------- ----------
batch processing
- long-term storage
- bounded analysis
- high latency
streaming processing
- temporary queueing
- unbounded computation
- low latency
-------- ---------------------- -----------
| Kafka | -- | Cassandra + Spark | -- | Cassandra |
| | ---------------------- | |
| | ---------------------- | |
| | -- | Event frameworks | -- | |
-------- ---------------------- -----------
Kafka
- producer
- consumer
- topic
- named queue
- can be partitioned
topic partitioning
- the queue become unordered
- because partition does not track order in other partition
strengths of batch + stream
- optimized subsystems based on operational requirements
- good at unbounded data
weaknesses of batch + stream
- complex to operate and maintain
Pattern 4 - Event Bus
- integration is a first-class concern
- life is dynamic; database are static
- table are streams and streams are tables
- keep your services close, your computer closer
Storing Data in Message Queue
- Retention policy (e.g. can be forever)
- high I/O performance
- O(1) writes, O(1)reads
- partitioning, replication
- elastic scale
first-class event - event or request ?
- request
- request
- response
- event
- produce
- consume
API Design: GraphQL vs. gRPC vs. REST
- They are different tools for different jobs
Design Considerations: there is always a best API style for the problem
API Styles
- Query APIs
- Flexibility
- For client to retrieve data from the server
- Flat File APIs
- SFTP
- Streaming APIs
- RPC APIs
- gRPC, thrift
- A component calling another components and hide the in-between networking
- Web APIs
RPC - Remote Procedure Call (gRPC, Apache Thrift, Coral)
- Model the function of the server
- Data over the wire (HTTP/2 + protobuf)
Advantages:
- Simple and Easy to Understand
- Lightweight payloads
- High performance
Disadvantages:
- Tight coupling
- the client and server need to understand each others
- No discoverability
- no way to understand the api without taking a look at the documentation
- Function explosion
- An api/function for an specific job; ends up with a lot of api/functions
Good For:
- Micro-services
REST - Representational State Transfer (json, ION)
-
Model the resource of the server
-
States machines over the wire
-
For API longevity, not for short-term efficiency
-
Reduce Server-Client coupling
Entry point
- client sending a request to the entry point
- server sending back the metadata of the api
e.g.
GET http://example.com
{
"conversations": {...},
"title": {...},
}
GET http://example.com/conversions
{
"count": 3,
"value": [...],
}
GET http://example.com/conversions/2/title
{
"title": "hello world",
}
Without any documentation, the user can understand how to use the api by taking a look at the metadata returned from the server.
Describe the operation on the resource
Advantages:
- Decoupled Client and Server
- API can evolve overtime
- Reuses HTTP
- HTTP verbs (GET POST UPDATE ...)
Disadvantages:
- No single spec
- Different people are having different understanding of REST
- Big payloads and Chattiness
- Returning a lot of reach metadata
- Chattiness: the client need to make a lot of API calls to accomplish an job
GraphQL - Graph Query Language
Model the query
- Requesting what exactly what the clients want
Schema definition
- Defined the types and query that the client can be made
e.g.
{
listCoversitions {
title,
message {
text
}
}
}
Advantages
- Low network overhead
- Typed schema
- Fits graph-like data very well
Disadvantages
- Complexity - harder for the backend than REST & RPC
- Caching - always HTTP POST (i.e. no http caching)
- Versioning
- Still early
| Coupling | Chattiness | Client Complexity | Cognitive Complexity | Caching | Discoverability | |
|---|---|---|---|---|---|---|
| RPC - Functions | High | Medium | Low | Low | Custom | Bad |
| REST - Resources | Low | High | Low | Low | HTTP | GOOD |
| GraphQL - Queries | Medium | Low | High | High | Custom | Good |
Use Case: Management API
Solution: REST Consideration:
- Focus on objects or resources
- Many varied client
- Discoverability and documentation
Use Case: Command API
Solution: RPC Consideration:
- Action-oriented
- Simple interaction
Use Case: Internal Microservice
Solution: RPC Consideration:
- Tightly coupled services
- High performance
Use Case: Data or Mobile API
Solution: GraphQL Consideration:
- Data is Graph-like
- Optimize for high latency
Use Case: Composite API - Backend for Frontend
Solution: GraphQL Considerations:
- Connect a lot of different frontends
- Connect a lot of different backends
- The middle service can use GraphQL to combine responses from different backends
Contract First Design Approach
Contract
- GraphQL => the Schema
- gRPC => protobuf
- REST => RAML, Swagger (OpenAPI)
APP
- mock against the contract
API
- mock against the contract
Product
- Merge the APP and API
Websocket vs. HTTP/2
https://www.infoq.com/articles/websocket-and-http2-coexist/
| HTTP/2 | WebSocket | |
|---|---|---|
| Header | Compressed (HPACK) | None |
| Binary | YES | Binary or Textual |
| Multiplexing | YES | YES |
| Prioritization | YES | NO |
| Compression | YES | YES |
| Direction | Client/Server + Server Push | Bidirectional |
| Full-Duplex | YES | YES |
is HTTP/2 a replacement for push technologies such as WebSocket or SSE? NO
Server Push vs Websocket Bidirectional communication
- Server push only push data down to the client cache
- i.e. the client application does not get notification for the event
Example
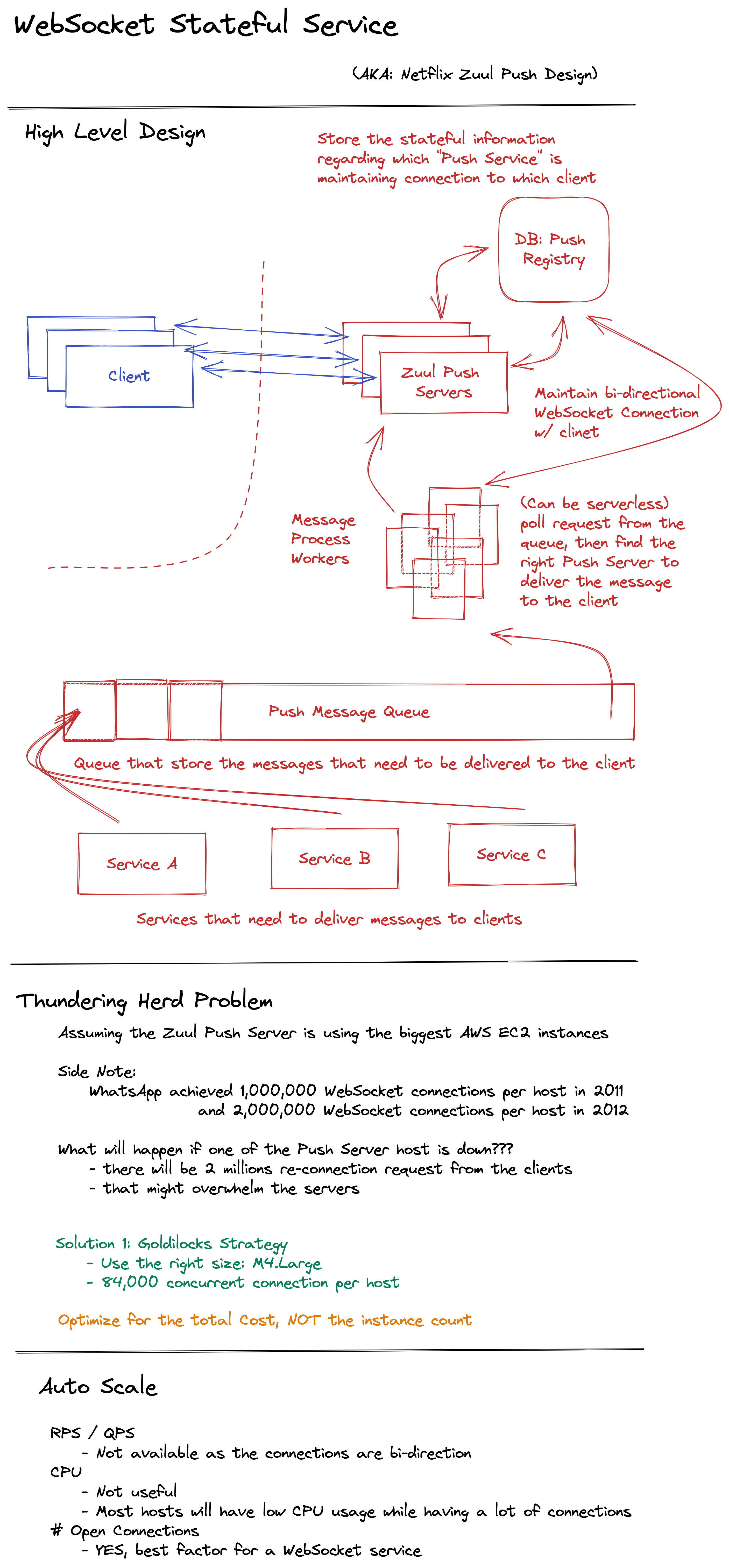
Netflix Zuul Push
Zuul Push Architecture
Zuul Push is the push engine at Netflix
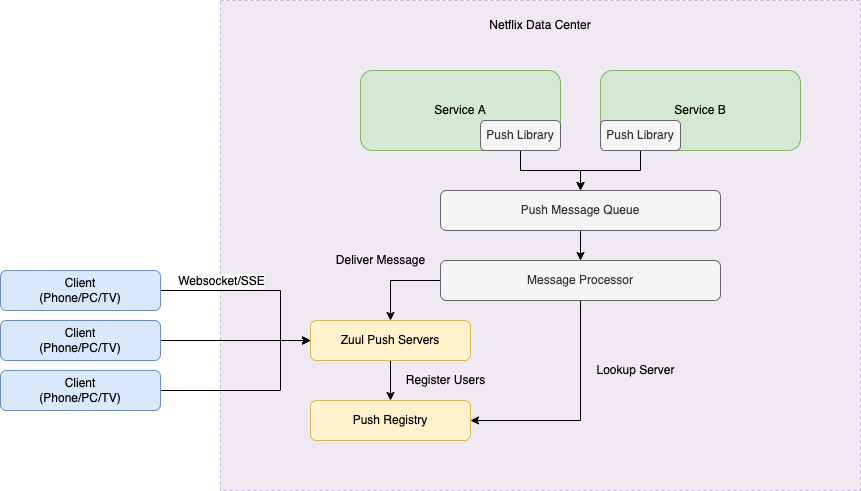
Workflow
- Client establishes an persistent websocket/SSE connection to the Zuul Push Service. The Client will keep the connection alive until the session is terminated.
- Zuul Push Service register the user and connection information to the Push Registry database.
- Service that need to send a push message (source of push message) use the Push Library (SDK) to send the message to the Push Message Queue.
- Message Processor
- pulls/retrieves an message from the Push Message Queue
- lookups the Push Registry to check which Zuul Push Service host is connected to the client
- delivers the message to the Zuul Push Service host
- Zuul Push Service host send the message to the Client
Background
Netflix use a recommendation engine to generate suggested videos for each user. i.e. the home page of the Netflix website for each user is different.
Push vs Pull
- Pull
- If too frequent - Overload the system
- If too infrequent - Data not fresh enough
- Push
- Most suited for Netflix
Push
Define Push:
- Persist
- Until
- Something
- Happens
The server push the data to the client instead of the client requests the data from the server.
Zuul push servers
Handling millions of persistent connections
Using Non-blocking async-io
C10K challengingL
- Supporting 10K concurrent connection on a single server
Traditional method:
- 1 Connection per Socket
- 1 Socket per thread
Socket --> Read --> Write --> Thread 1 Socket --> Write --> Read --> Thread 2
Async I/O
Socket --> write callback --> single thread --> read callback --> Socket
Netflix use Netty for the Async I/O
Push Registry
Push registry feature checklist (the database used as the push registry should have the following feature):
- Low read latency
- Record expiry (e.g. TTL)
- Sharding
- Replication
TTL -> If the client failed to terminated the connection proactively; the system need to use TTL to remove the registered entry from the Push registry.
Good choice for Push Registry
- Redis
- Cassandra
- AWS DynamoDB
Netflix use Dynomite
Dynomite = + Redis + Auto-sharding + Read/Write quorum + Cross-region replication
Message Processing
Message queuing + route delivery
Netflix use Kafka
Message sender use "FIRE and FORGET" approach:
- Drop the push message into the queue
- Carry on with other tasks
Cross-Region Replication
- Netflix use 3 AWS region
- Use AWS Kafka queue replication
Queue:
- Hard to use single queue
- Different queues for different priorities
Message processor
- multiple message process in parallel
- auto scale based on the number of message in the queue
Operating Zuul Push
Different from the Stateless services
Stateful:
- Persistent connections - long lived statble connection
- Great for client efficiency
- Terrible for quick deploy/rollback
Deploy/Rollback
- Client are not automatically migrate to the newly deployed servers
- Thundering herd: If keep the connection at once, the client would try to connect to the new servers at once (overwhelm the servers)
Solution:
- tear down connection periodically (from the server side)
- randomize each connection's lifetime (jitter)
- result: randomizing connection lifetime on reconnect peak
- Extra: server ask client to close its connection (the party terminate the TCP connection might have a FD on linux remain open for up to 2 mins)
Optimization
How to optimize push server? (most connection are idle)?
first approach: big ec2
- big EC2, as many connection on the single server as possible
- Issue: if a server is down: Thundering herd happends
second approach: goldilocks strategy (just right)
- m4.large (2v CPU)
- 84,000 concurrent connection per ec2
Optimize for cost, NOT for instance count
How to auto-scale ?
RPS (request per second) ? NO
- No RPS for push servers
CPU ? NO
- Instances is not limited by CPU
Open Connection ? YES
- Only factor that is important to a push server
AWS Elastic Load Balancer cannot proxy WebSocket
ELB does not understand websocket Upgrade request (A special HTTP request)
Solution: Run ELB as a TCP load balancer (NLB) (Layer 4)
AWS ALB not support WebSocket
Use case for Push System
- On-demand diagnostics
- Send special diagnostics to devises
- Remote recovery
- User messaging
References
- Susheel Aroskar- Scaling Push Messaging for Millions of Devices @Netflix
AWS Fargate
Questions
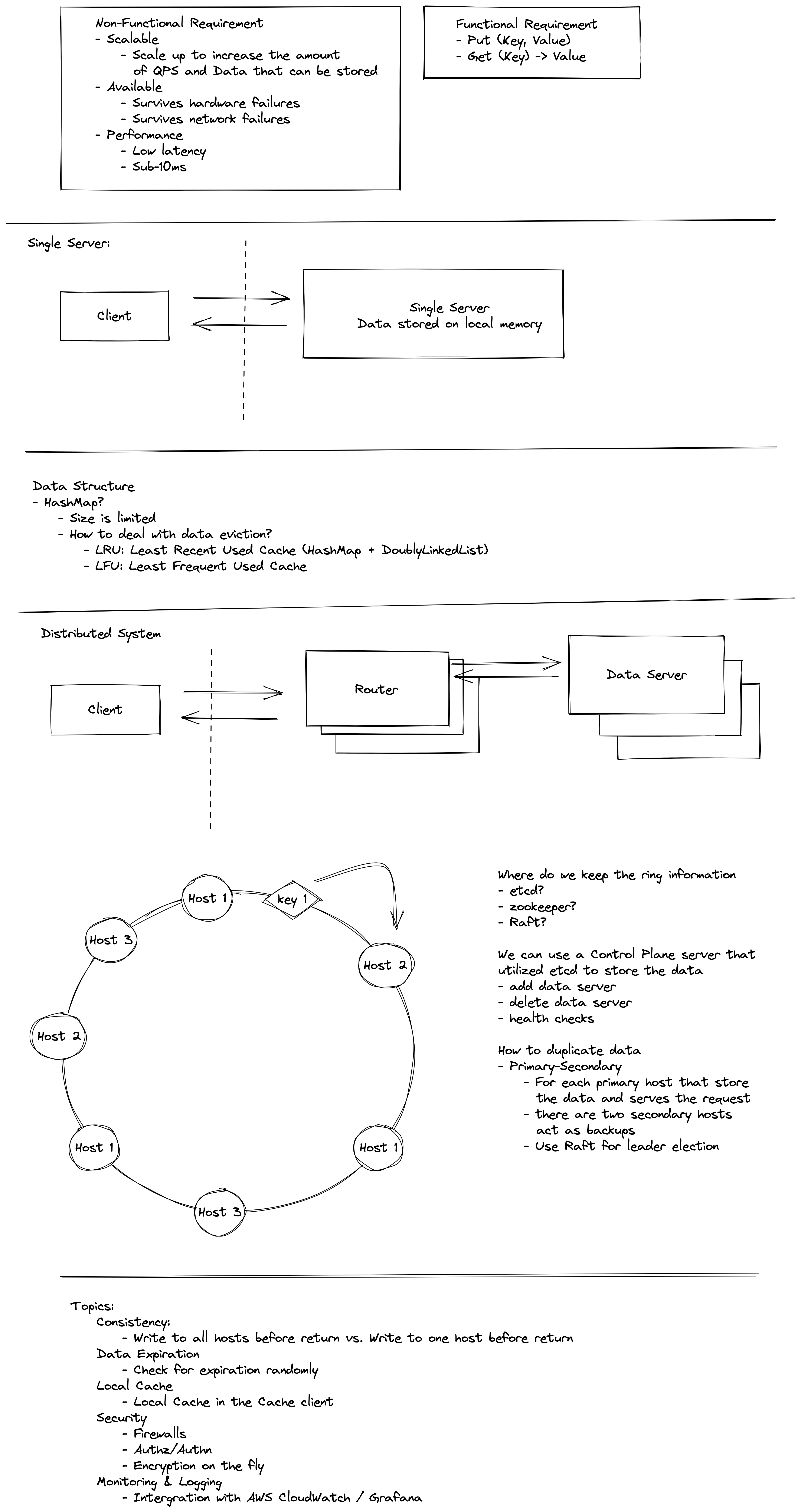
Design Key-Value Store
theorem
Design a Rate Limiter
Question to ask
- Where is the rate limiter been used?
- For a gRPC/REST api on the server side?
- For a client side - to avoid sending too many request to the server?
- For DDoS prevention?
- Do we impose a hard limit or a soft limit?
- Stop serving the request if it hit more than exact 100 QPS?
- Or just roughly around 100 QPS?
- How do we identify the user?
- Using IP address?
- user account?
- AK/SK?
- The scale of the system?
- QPS?
- Number of user?
- Type of system
- Distributed system? Monolith?
- Single region? Cross-region?
- Where is the rate limiter located?
- A pass-through gateway? Frontend service?
- A microservice that determine if a request should be processed?
- How do we inform the user?
- Error code
- HTTP Code 429 - Too many
Off the shelf solution
- AWS: AWS API Gateway - configure throttling for the API
- GCP: GCP API Gateway - quota and limits
- Azure: Azure API Management - advanced api throttling
Rate limit algorithms
- token bucket
- leaking bucket
- fixed window counter
- sliding window log
- sliding window counter
High level design
Where to store the counter/queue/log?
- not in disk (not local disk, not dynamodb, not mysql)
- in memory (local memory, redis, memcached)
Data consistency (race condition & )
- require atomic operation - INCR redis operation
synchronization issue
- more than one rate limiter servers, different server is storing different states
- solution:
- consistent hashing
- using a shared data store - redis / memcached
TODO???
- what if we want to rate limit the amount of open gRPC stream / websocket connection ?
- assuming an user can have 5 stream at a time
- reject new connection is there are 5 stream open
References
- Alex Xu - System Design Interview - An Insider's Guide

Design Distributed Cache
Design Payment Networks
Design WebSocket Server
Design Prometheus
Terminologies
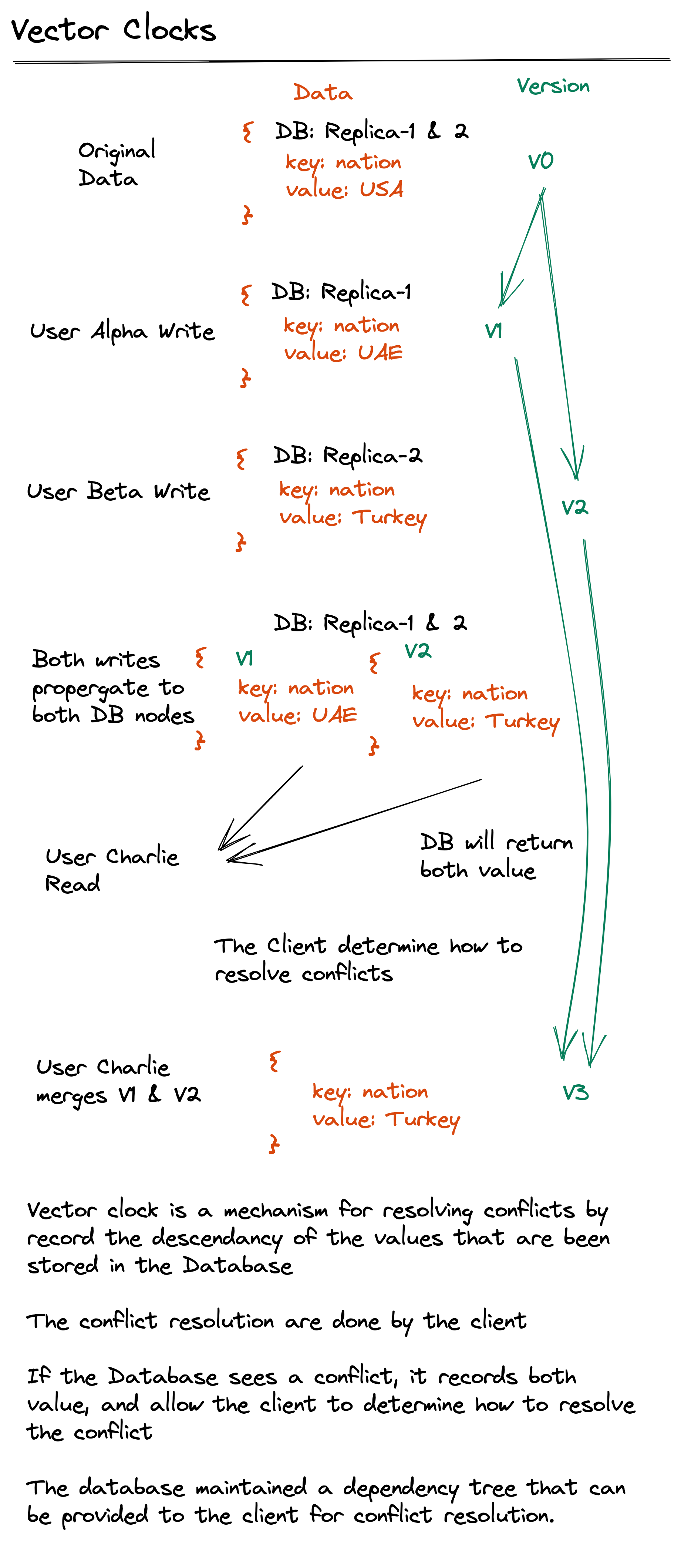
Vector Clocks
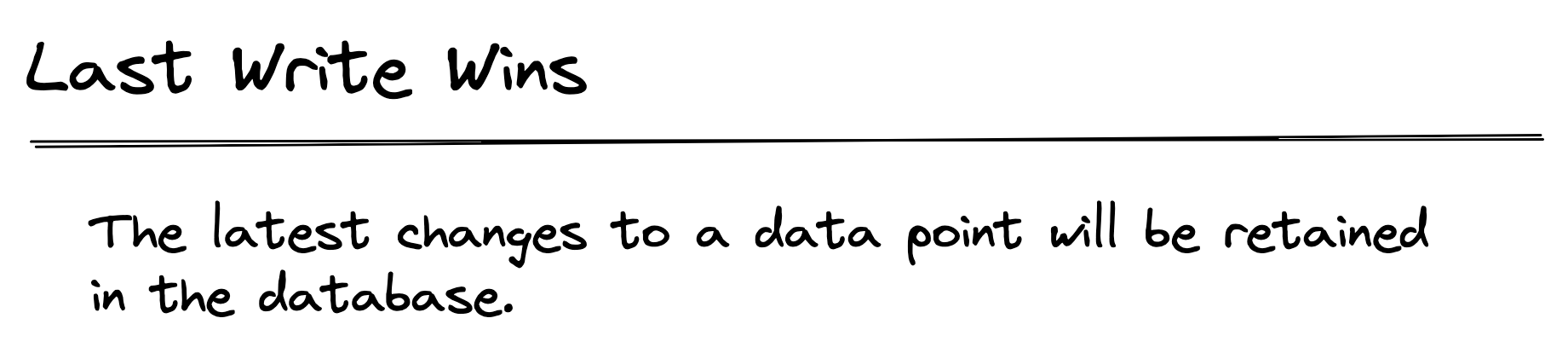
Last Write Wins
Hinted Handoff

Strict & Sloppy Quorum

Confidence
- Traits of Confident People
- Postures: How we look?
- Smooth gestures
- More eye contacts
- Gain the command of the room
- Time
- Take my time to do things in my pace
- Postures: How we look?
Career Path
- Avoid decision/analysis paralysis
- Do not spend weeks/months to figure out what to do.
- Just do it and switch course as needed.
- Ignore "follow your passion"
- Most people don't know what is their "passion"
- Hence, the passion can be only discover through doing
- Focus on the PEOPLE
- People are the most important contributor to your success
- Access new opportunity
- Impact
- Alignment with the business
- The value of your work for the business
- Impact and be valued
- Work on high priority projects
- Try to work on the CORE of the business / project
Imposter Syndrome
- Accept imposter syndrome
- Problem solving
- Decompose the problem and get started
- Keep a job diary and track how you spend your time
- Asking questions
- Asking > being stuck
- do not spend more than 15/30 mins been stuck
- articulating the questions helps you learn - write it down
- build social capital if done correctly
- Ramping up on a new team
- career cold-start algorithm
- Find someone on the team and meet them for 30 mins
- Asks them for a brain dump of
- what they do?
- biggest challenges
- who else to meet
- repeat the above process until the same names start coming up in num 3
- career cold-start algorithm
- Get high-quality feedback
- ambiguity causes anxiety
- schedule dedicated 1:1s for feedback, ask questions which force deeper reflections - with mgr and techlead - ask deeper questions
- e.g. last week during the xxx meeting, i does not feel well and dont know how to contribute. what suggestion/feedback do you have on that specific meeting
- in code reviews, proactively identify areas where you have concerns or questions
- Helping others
- Create a friendly environment: encourage questions
Routines and Skills
- Brag Document
- Record the event in detail every time when you have done something impactful
- Balance between low and high impactful tasks
- Do not waste all of the time on low impact tasks
- Keep a good balance between low and high impact tasks
- Interview Skills (as an Interviewer)
- Active listening
- Communication
- Calibrate the skill to rate other engineers
创业
思维框架
How can I predict if an investor will like my idea?
Youtube: Kevin Hale - How to Evaluate Startup Ideas
-
Problem: 一切的创业都源于「解决问题」
一个好的问题至少有以下特质中至少一项,理想情况下满足多项
- Popular: 很多人有这个问题
- Growing: 增长性,越来越多的人有这个问题,并且这个问题增长的速度快于其他问题
- Urgent: 紧急性
- Expensive: 收入可行性
- Mandatory: 被解决的必要性
- Frequent: 可重复性
理想情况
- Popular: 1M+
- Growing: 20%/year
- Urgent: Right Now
- Expensive: $B
- Mandatory: Law Changed
- Frequent: Hourly
B = M + A + TMotivation Behaviour Ability Trigger- Motivation: 我有这个问题,并且我想解决它
- Ability: startup 提供的解决方案
- Trigger: 什么「外界环境因素」会提醒我要用这个解决方案来解决我的问题
-
Solution: Do NOT start here
永远要从「问题」入手,而非从「答案」入手
SISP: Solution In Search of a Problem
-
Insight: Unfair Advantages Related to Growth
- Founders: 是不是世上只有十个人能解决问题,而你是其一?
- Market: 市场是否在 20% 每年的速度增长?
- Product: 10x 解决方案,新的产品是否比已有的方案好十倍
- Acquisition: $0 获客成本为零
- Monopoly: YES/NO
公司价值?
-
衡量公司价值的第一标准创业能否持续的前提
- 核心目标:满足用户需求
- 用户是否愿意买单
- 衡量好坏的第一标准:赚不赚钱
商业模式?
-
简单:
- 起点简单
- 解决方案简单
- 业务模式简单
Ideas
2024-12-17: 中文 Guided Meditation 软件
2024-12-17: 香港和中国会计 SaaS
2024-12-20: 中文、日文 竖排版 epub 阅读器
2024-12-31: Meditation Timer APP
Books
创业 36 条军规
作者:孙陶然
已读:2024-12-15
笔记
股东协议
- 公司方向
- 股东义务
- 决策机制
- 退出机制
创业三座大山
- 找方向:做出一个有人愿意花钱买的产品
- 找人
- 找钱
冒险
创始人要有冒险精神,打破常规,不按牌理出牌。
- 冒险让自己特别起来
- 冒险提供别人不能提供的服务
- 冒险出品别人不制造的产品
引用
第一部分 创业的真相
军规2:梦想是唯一的创业理由
创业就是:
- 对某某方向有痴迷的梦想。
- 在个人兴趣、个人特长及市场需求之间找到一个「产品点」。
- 组建一个团队。
- 调动团队内外的全部资源围绕这个「点」死磕
如果可以选择,最理想的职业道路是本科即可,不必读研究生(除非你想做学问),本科毕业走出校门进入大公司工作两三年,然后进入小公司或者去创业。我不赞成在大公司待太久,我认为在大公司待5年以上的人基本就废了,进入眼高手低一群,成了温室里的小白鼠,生存能力退化,却又自视很高。这样的人一旦离开大公司的环境,身上的品牌光环退掉之后,基本上就是“鸡肋”,一定会跌跟头的。
军规3:选择正确的创业方向
抓住刚需是成功的不二法门
我认为根本上决定公司经营成败的,是市场份额;根本上决定市场份额的,不是营销而是产品;决定产品成败的,是需求。
对于自己的产品,要经常问自己四个问题
- 哪些人需要我们的产品?
- 他们用我们的产品干什么?
- 我们的产品是否足够好?
- 我们的价格是否可以接受?
用户的需求分为真需求(needs)和假需求(wants),一定要区分清楚。
市场规模是决定性的,决定了你最终能够达到的高度。
军规6:凡事只能靠自己
创业路上有三座大山:找方向、找人和找钱,爬过这三座大山企业就基本上度过创业期了。这三座大山原则上只能靠你自己爬,不能指望外来的和尚,外来的和尚你请不起,请来了他们也念不好你这本创业经。
宁愿前进速度慢一点,宁愿收益没有最大化,但是一定凡事都要有 B 计划,任何时候都要留有余地,目的就是随时准备应付预想不到的意外,随时准备自救!
军规7:干部要靠自己培养
中国人的商业道德水准也不是很高。中国人的民族性也不支持,中国人讲究宁为鸡头不为凤尾,经理人干几年带着客户出去创业和东家竞争的案例比比皆是,尤其是那些创业门槛低的行业,这种现象更是普遍。
第二部分 创业者需要特殊材料制成
军规8:要有预见性
对于创始人来说,即便不能预见国家宏观形势的未来,也要去预见本行业的未来;即便不能预见本行业的未来,也必须预见本企业的未来,否则失败是必然的。
军规9:要敢于冒险
事情的确定性与可能性成反比,追求可能性必然要放弃确定性,追求确定性必然会丧失可能性。一件事情的确定性越大,就意味着可能性越小,而可能性越大也就意味着确定性越小。
所有的成功者都是敢于冒险的人,天鹅肉从来都是被第一个敢张嘴的癞蛤蟆吃掉的。
如何能够在市场上有一己之地?只有一种办法,冒险!冒险让自己特别起来,冒险提供别人不能提供的服务,冒险出品别人不制造的产品,打破常规,不按牌理出牌。
军规11:心里强大者胜
创业者必须是一个心力强大的人,必须有「断腿求生」的气魄,必须有股子对自己的狠劲儿。
第三部分 创建公司有规律
创业期最忌讳的是好高骛远小公司大做,最重要的是找方向,能不能做出一个有人愿意花钱买的产品,并找到一种方法源源不断地把产品卖出去,这是创业起步的核心。
军规12:股东宁缺毋滥
不选非市场化的机构作为股东。
因为中国的战略投资人有一种将战略投资作为竞争手段的倾向,和他们打交道还是小心为妙.最常见的情况是,引入了战略投资者,非但没有享受到对方的战略资源为自己服务,反而受到对方各种掣肘,让你为对方的战略服务,这样的战略投资者一旦引入后患无穷.
所以创业之前必须考虑到股东之间产生分歧的可能,这也是事先要签股东协议的原因所在,大家约定好规则、认同规则才能成为股东,如此才能为公司奠定一个长远、坚实的根基。
军规13:实现要签股东协议
股东协议应该约定哪些事情呢?我认为至少应该包括四个问题:公司方向,股东义务、决策机制以及退出机制等原则问题,而且不但要制定规则还要制定执行细则。
要约定股东退出机制。退出机制是必须事先约定的.
军规14:建立现代企业制度
股东之间的比例关系,一般以大股东持股不超过45%,二股东不高于30%为佳。股份比例有两个原则要把握:一是大股东和小股东之间的股份差距不要太大;二是企业一定要有一个大股东。在处理股份比例上,不宜一股独大,这会使大股东的意志高于董事会的决策;也不宜过于平均,如果所有小股东加起来还没有大股东大,或者大股东大很多,都会有问题。因为企业必须要有一个大股东,尤其对于创业期的企业,需要英雄主义,需要创始人敏锐的判断力和非常坚定的决心和狂热,需要有人在所有人都无法担当的时候以一种无限责任的心态来担当。如果没有一个股东把企业当成自己的事业来做,企业不可能做起来。
军规15:企业文化必须一开始就建立
企业文化
- 第一,企业文化很重要,必须一开始就建立
- 第二,如何建立自己的企业文化
- 第三,如何才能贯彻企业文化
如何「想」
- 统计分析:用数字说话,用环比、同比、百分比说话。
- 一页报告:所有报告用一页纸写完,佐证及材料附后。
- 三条总结:所有问题,用三条说清楚。
军规16:尽早验证你的商业模式
你卖什么?怎么收费?怎么卖?这是商业模式的核心,一份几十页的商业计划说不清楚这三个问题就说明创业者根本不知道这三个问题的重要性,根本不知道何为商业模式,让投资人怎么敢投资?
找方向、找人、找钱,其中找方向,就是要找到自己的商业模式并验证其是成立的,是可以开始复制的。
好的商业模式应该是简单的、重复消费的、可以多角度挖掘用户价值的
好的商业模式有以下几个特点
- 简单:首先产品要简单
- 重复消费:好的商业模式用户都是重复消费的
- 多维增值:拥有用户,能够多维度开发用户价值,让用户不断延展消费
以我的经验,有两类商业模式风险很大:
- 一类是综合性解决方案型商业模式,其特点是业务需要多个前提条件,而原则上需要3个以上前提的商业模型基本上是不成立的,因为即便每个前提我们都能够达成90%,3个前提你都达成的可能性也只有70%,这类商业模式赚钱只是理论上的可能。
- 还有一类风险很大的,就是超越逻辑的商业模式。逻辑是商业模式的基础,不符合逻辑的模式成功是极偶然的,而失败是必然。多年来我们看到过很多绚丽的商业泡沫冉冉升起随后轰然破灭,盖因如此。其实很多人对于团购的质疑也在于此,消费者来团购是因为团购便宜,一旦团购网站降低折扣或者商家完成推广后恢复正常价格,那用户还会来吗?如果不来那你现在烧钱累积起来的用户有价值吗?
军规17: 先赚到钱再研究发展
对创业公司而言最重要的是先找到一个能赚钱的商业模式再徐图发展。
很多时候,这种羊毛出在猪身上狗埋单的商业模式太脆弱,因为链条过长,一旦其中的某个链条不成立,最终的结论就不会成立,我还真没有怎么看到这类成功的案例。
不愿意赚当下的小钱幻想着赚未来的大钱,这是创业者经常容易犯的一个错误.
「速度」:你多快产生销售?多快打平?多快产生利润?“速度”二字决定了你作为创业者的本领大小。现金流是创业之本,利润是创业之魂。
赚不赚钱是衡量公司好坏的第一标准
第四部分 经营有方法
军规18:学先进傍大款走正道
每当我们想拒绝学习的时候,就会抛出一个理由“国情不同”:我们是特殊的,所以您那些做法和思路是我们无法学习的。这其实是一个陷阱,世间绝大多数事情并不存在“特殊性”问题。我们失败就是因为我们认为自己是特殊的。
军规19:创新是最好的创业武器
需求是创业的基础,没有需求就没有市场,没有市场就没有创业。
只有创新才能创业,所谓成功就是把别人认为的不可能变成可能的创新过程,所谓创业就是发现消费者的新需求,并找到一种方法满足他们需求的创新过程。
军规21:集中兵力解决主要矛盾
对于处在创业头两年的公司,你不需要考虑什么宏伟的战略规划,那东西对你来讲只有害处没有益处,你的战略就应该是「集中全部资源,围绕着你找到的那个撕开市场的点,撕开一个口子并最大化地扩大战果」
公司发展的不同阶段主要矛盾各不相同,创业期公司的主要矛盾是业务问题:找方向,即找到自己的商业模式,只有找到了商业模式公司才能前进,创始人必须集中兵力来解决这个主要矛盾。
军规23:不要搞大跃进
- 创建企业时:要从实体上和文化上把企业创建起来,不能只在实体上创建企业而不创建企业文化。
- 企业创建后:要找方向、找人和找钱,做出有人愿意买的产品。
- 做产品:要抓住用户的刚需做深做透,互联网时代做成品还要小步快跑,迅速上线,不要求大求全。
- 产品投入市场:要找到可复制的销售方法,把产品源源不断地卖出去。
- 随着企业做大:管理问题也会凸显出来,创始人必须要学会管理,过管理关。
军规25:做減法
纵观历史,所有的企业成功都是源于把一个产品做火了,而非做了很多半火不火的产品,对于创业公司而言,只要抓住用户的一个需求将其满足到极致就可以成功,也唯有如此才能成功。
互联网时代的创业更是如此,抓住一个刚需,快速推出产品,快速上线,边运营边完善,小步快跑迭代开发,这是互联网企业创业的不二法门。
绝大多数成功的商业模式都是非常简单的,第一是起点简单,就是为了解决用户的一个强需求而已。第二是解决方案简单,创业者的智慧在于找到了简单而巧妙的方法解决了用户的难题。第三是业务简单,专注而不求全、不求大、不求规范,集中全部资源将最核心的事情做到极致。
中国几乎所有企业的“发家史”都是三部曲。第一部,企业推出了一个好的产品或者服务占领了市场。第二部,企业开始借助资本的力量进行布局、扩张。第三部,逐步成为行业领军企业,形成自己的生态链,依靠综合竞争力参与竞争。这三部曲的核心都是找到突破点然后突破这个突破点,创业期就是要紧盯用户的需求,选择一个突破点,然后集中全部资源和力量撕开这个突破点。
第五部分 管理是门科学
军规26:先打样再复制
其实企业经营的本质很简单,就是两件事:做出有人愿意买的产品,找到一种把产品源源不断卖出去的方法,这两件事做起来也很简单,先仔细研究认真分析设计出我们认为最可行的方案,然后亲自去试点,在试点中修改,如果试点不成功,重来此过程;如果试点成功,快速复制。企业经营就是如此而已。
军规27 管理是一门专业
小公司的6个管理天条:
- 点式战略,撞了南墙也不回头。不制订大而全的N年规划以及所谓的中期战略,而是找到一个市场的突破点,然后集中全部资源围绕这个点展开经营,最大限度地突破该点并向四周扩大战果。
- 跟我冲。不设只管人不管事的领导,总裁应该直接兼任前方总指挥,副总必须兼任下属关键部门的经理。
- 只做最低限度的管理。我们都喜欢规范和有序,但其实是公司越大规范的价值才越大,对于小公司,花精力去关注管理的规范,直接后果就是效率的降低和成本的快速提高,而且会扼杀创新。
- 做减法。成功,需要的是做好一件事,做再多的事如果做不好也不可能成功。对于小公司而言,要集中资源专注在主业上,甚至专注在对于本年度目标有贡献的事上。
- 新人做新事。公司拓展新业务很正常,最容易出的问题是让老人去做新事,导致老事新事一起混乱。正确的做法应该是:老事定指标精细化管理,新事设目标鼓励试错,以项目小组的方式工作,新事新人做,不要增加老事的工作量。
- 先打样再推广。不论是市场还是管理,甚至是新产品,都要先在小范围内试点,试点成功再推广,切记一上来就大规模推广。不要担心试点丧失市场时机,做好试点可以避免犯错,磨刀不误砍柴工。而且,试点不怕慢,但必须细致,一把手亲自参与,关注每个环节,找到可以复制的模式,试点成功了推广必须快。
第六部分 融资有窍门
军规32:资本只是你的一段情
事后我才知道,师兄的基金在行业内是有名的傲慢,他们对我还是比较客气的。其实完全搞反了,创业者才是最高贵的,没有创业者就没有基金的市场基础和收益来源,作为投资人,如果不尊重创业者,不在相互平等的基础上和创业者对话,是不可能获得成功的。
如果你同时与一家以上的投资公司谈判投资条款,「背靠背」是必要的,千万不要讲出另外一家投资商的名字和他们开出的投资条件,要不然你得到的将不是两份互相竞争的 Term Sheet,而是一份联合投资的 Term Sheet,基金肯定会互相打电话联系的。当你想拿别家投资公司的报价来压价时,当心他们会联合起来跟你讲价。
对于天使投资人而言,除了投钱之外,还应该是一个联合创业者,用你的经验去充当创业者的教练,最好是用自己的「大资源」来帮助「小创业者」,而不是「大鱼吃小鱼」倾轧创业者。
军规33:能融资时要尽快融资
现代创业,如果不借助资本的力量很难在竞争中脱颖而出。虽然融资解决不了经营上的问题,虽然有时候创业期的公司资金太多反而会增加企业犯错误的机会,虽然钱不是万能的,虽然创业初期企业的困境绝大多数不是靠钱能解决的,但还是必须融资。
不融资就会输在起跑线上
如果要融资,一定要在企业不需要钱的时候去融资。
争取和最强的资本结合
雷军在「评估创业项目的十大标准」中给出了评估团队的6条标准,可以从另一个角度供大家体会:
- 能洞察用户需求,对市场极其敏感。
- 志存高远并脚踏实地。
- 最好是两三个优势互补的人一起创业。
- 二定要有技术过硬并能带队伍的技术带头人(互联网项目)。
- 具备低成本情况下的快速扩张能力。
- 履历漂亮的人优先,比如有创业成功经验的人会加分。
最难的是(1)和(5)。雷军认为如果创业团队达到上述6条标准,只要有梦想,坚持下去,就一定会成功。但同时创业团队必须找到合适的创业方向,才会真正成功。
如何判断项目是否值得做呢?雷军总结了4条标准来选择项目:
- 做最肥的市场,选择自己能做的最大的市场。
- 选择正确的时间点。
- 专注、专注再专注。4. 业务在小规模下被验证,有机会在某个垂真市场做到数一数二的位置。
一句话来表达就是:在对的时间做一件对的事,并且要做到数一数二。
军规35:不要让投资人替你决策
投资条款。对于大概率事件条款要寸士不让,例如董事会的权力、独立投资权限、追加投资权限等,投资人会要求各种一票否决权等特殊权力,但创业者必须对这类条款据理力争,坚决守护底线,例如:
- 投资人的一票否决权
- 回购条款
- 上市时间表
基层女性
作者:王慧玲
已读:2024-12-17
引用
成长的过程中必然会有一些人辜负你的善良,你要做的就是把他们从生活里清除,不要让他们改变你。
无论你的生活在面对什么,你都要坚信一点:你是有力量改变的,你是有选择的,生活没有你想的那么糟糕。相信我。
很多子女也表示,父母从来没有向自己索取什么,或为了自己而怎么样。但是,大家想一想,他们真的没有索取吗?他们所有的付出,真的不需要回报吗?正如前面那位阿姨一样,她不需要回报吗?他们是索取的,只不过他们需要的回报不是金钱而已。他们要的是你听话,学业、事业有成;要的是在填报志愿、择业择偶时听他们的安排;要的是你早日成家,这辈子必须结婚生子;要的是让他们有面子,在外面有谈资;要的是你的陪伴,不远走远嫁,就近读书、工作;要的是你在跟前对他们的孝顺、照顾;要的是你接受他们在你的生活中无孔不入、无处不在;要的是你发自内心地认为,他们所做的一切都是因为爱你,都是为你好。
很多人的父母一辈子都没有自己的生活,尤其是在一些单亲家庭。孩子可能会说:“我的母亲只有我。”对此,我的态度是,每个人都要为自己的人生负责,你的母亲是一个成年人,你应该鼓励她去解决自己的问题,经营自己的生活。如果她无法做到,只想黏着你,不停地抱怨,把自己对人生的失望、愤懑,像毒气一样倒给你、腐蚀你的话,你迟早会被它们吞噬。这些负面情绪会影响你的健康、判断和人际关系,全方位影响你的生活。
成年后的第一步,就是要学会做自己的父母,重新教育自己,审视自己过往被父母影响的价值观和思维模式,把糟粕从大脑中清除。如果你的精神不先富裕起来,不去打破固化思维,这一生便很难有突破。思想上的穷才是真正的穷。
要清醒地认识到,你的精神世界只有你一个人,永远都是你一个人。若有人让你依靠,抱着感恩的心态,同样积极地回馈给他依靠,但是永远不要去依赖,不要把自己的幸福、喜怒哀乐寄托在别人身上。
能做开放空间的工作,就不要做封闭空间的工作,比如西餐厅服务员和电子厂流水线工人之间,一定要选择前者。因为前者能让你每天接触不同的人,应付相对复杂的环境,可以学到更多,而在一个环境相对封闭的流水线上,几年下来也只是新手和熟练工的区别,是没有发展前途的。
归根结底,幸福才是我们的追求,而不是婚姻和车、房本身。
希望大家在这个世界上能清醒理智、内心坚定地活着,真正明白什么对自己最重要,选择内心真正想要的、想玩的游戏,而不是被各种宣传扰乱心智,被翻滚浪潮中的各种理念裹挟着向前走。
这就是为什么我建议年轻人把结婚生子、买车买房排除出你的人生计划表。结婚生子应该是顺其自然发生的,而不是目标和任务,它们跟其他事一样,都只是人生的选项。
精神世界越丰富的人,越注重精神世界的交流,而精神越贫瘠,审美标准就越单一,就越追求感官上的刺激。从当下男性的择偶观上也可以看出一些端倪,真正有知识、思想进步的男性,相比女性的外貌,更看重女性的个人能力、个人魅力、兴趣爱好,以及两个人的精神世界是否能产生共鸣。而底层男性则更加看重女性的外貌,以及跟生育能力挂钩的年龄。
总之一句话,就是去折腾,树挪死,人挪活。放眼全世界,看看那些活得让人仰慕的人、对世界有贡献的人、活出自我的人,哪个不是从年轻的时候就生命力旺盛、喜欢折腾的人?
当你处于物质贫困的状态时,遇到爱情的概率是很低的,极有可能会遇到一个跟你同样物质、精神贫困的人。那些真正精神富裕、有能力爱别人的人,也在寻找精神世界富足、能产出和给予爱的人。
城與不確定的牆
街とその不確かな壁
作者:村上春樹 譯者:賴明珠
已讀:2025-01-05
引用
意識,是指腦察覺到本身的物理狀態。
這裡是高高的磚牆內側,還是外側?
我想說的就是這樣。一旦嘗過真正純粹的愛的滋味,內心的一部分就等於已經受到照射而發熱過了。某種意義上是燒完了。尤其那份愛還因為某種原因被中斷的話。那樣的愛對當事人來說是無比的幸福,同時也是麻煩的詛咒。
在這段人生之中,我沒有身為自己,身為自己的本體活著的真實感。有時會覺得自己只不過是影子而已。在這種時候,我總會感覺自己好像只是模仿自己的形體,巧妙地扮演自己活著似的,心情無法鎮定。
本體和影子原本就是表裡一體的。
最終的個人圖書館。
什麼是現實,什麼不是現實?不,甚至該問隔開現實與非現實的牆,真的存在於這個世界上嗎?牆或許存在,我想。不對,那無疑是存在的。但那是一道完全不確定的牆。會根據情況、根據對象改變硬度,改變形狀。就像生物一樣。
嘿,你懂了嗎?我們兩人,都只是別人的影子而已喲。
但是,我想,現實可能不只有一個。所謂的現實是要從幾個選擇中,選出自己想要的才行。
這座城只存在著現在這個時間。沒有蓄積。一切都會被覆蓋、被更新。這就是我們所屬的世界。
無論是真的或假的,其實都無所謂。事實與真實是不同的兩件事。
我試著想像那樣的光景。我爬上薩摩亞某個島上最高的椰子樹頂端(大約有五層樓高),而且想再爬得更高。但當然樹長到那裡就停止了,前方只有蔚藍的南國天空。或者,只有一整片廣闊的無。我看得見天空,卻看不見無。所謂的無,終究只是概念而已。
「換句話說,我們離開了樹木,處在虛空之中是嗎?身在一個無處可抓的地方嗎?」
少年微微但堅定地點頭。「沒錯。可以說我們正浮游在虛空之中。這裡沒有可以抓住的東西。不過還不會墜落。開始墜落需要時間的流動。時間如果停止的話,我們會一直處在浮空的狀態。」
「而在這座城,時間是不存在的。」
少年搖搖頭。「在這座城裡時間也是存在的,只是沒有意義而已。雖然結果是一樣的。」
「換句話說只要留在這座城的話,就可以一直浮在虛空之中嗎?」
「理論上是這樣。」
我說:「那麼,如果因為什麼因素讓時間再度開始動起來的話,我們就會從高處掉下來,而且那可能會是致命的墜落。」
「恐怕是。」黃色潛水艇少年乾脆地說。
「也就是說,我們要維持自己的存在,就不能離開這座城。是這樣嗎?」
「恐怕我不到防止墜落的方法。」少年說。但是要化解致命傷害的方法,並不是沒有。」
「例如什麼樣的方法?」
「相信。」
「相信什麼?」
「相信地面上有人會接住你。打從心底這樣相信。毫不保留,完全無條件地。」
你的心就像天上飛的鳥一樣,高牆也無法阻礙你的心振翅飛去。
所謂的真實並不是存在於一個固定的靜止狀態中,而是在不斷遷移 = 移動的諸相中。
马督工书单
- 梁山夷家 林耀华
- Der 18te Brumaire des Louis Napoleon Karl Marx
- 儒法国家:中国历史新论 赵鼎新
- 东周战争与儒法国家的诞生 赵鼎新
- 李守信自述 李守信
- Il Decameron Giovanni Boccaccio
- Das Kommunistische Manifest
- 临高启明
- 钢铁是怎样炼成的
- 1984
- 特别的人民,特别的国家:美国全史
- Uncle Tungsten: Memories of a Chemical Boyhood
- 大目标:我们与这个世界的政治协商
- 旧制度与大革命
- 解放战争 王树增
- 弱传播 邹振东
- 枪炮、病菌与钢铁
- 时间地图:大历史
- 1493: Uncovering the New World Columbus Created
- 1491: New Revelations of the Americas Before Columbus
- 沙县文化小吃大观